Self-Defining Cores in Solr
How the Solr import itself can help you detect the structure of your data
I recently wrote that Solr can be populated from json without any pre-configuring or pre-defining of data fields and data structures. This feature is very handy. It permits injecting a lot of data without knowing the full structure of it, and having Solr tell you about the structure once it is imported, so that you can decide on it with a certain support.
Real data is out there
Let’s find an example dataset and see how this works. We could just make one up, but it’s a lot more fun to use real data, and it’s also more fun to have some size on the json file that we shall use. I found a nice dataset containing Twitter tweets from a couple of hours on the 26th of May, 2018 over at kaggle.com.

The event that those tweets are about is also available with Spanish commentary. You’re free to use other datasets, of course. As long as the json structure is ok and the data are consistent, you’ll be fine. But in the following, I’ll stick to the one mentioned above.
First download and unpack the dataset. In my case, I got 1.9Gb of json in a file named TweetsChampions.json.
Then create a new Solr core and tell Solr to use schemaless mode. This is the important trick. In this mode, Solr will guess the best field type for each field it encounters when importing the json data. The instructions are sent thus:
/opt/solr/bin/solr create -c championsTweets
/opt/solr/bin/solr config -c championsTweets -p 8983 -action set-user-property -property update.autoCreateFields -value trueAnd then it’s time to import the data! We will use the update command for that. It’ll take a while for Solr to chew up all the json, so go get a coffee while it works. Here’s how to start the process (there is no update command to the /opt/solr binary, so we use curl to access the Solr http API, and since the file is rather big, we send it off in chunks):
curl -X POST -H 'Content-Type: application/json' \
-H 'Transfer-Encoding: chunked' \
'http://localhost:8983/solr/championsTweets/update/json/docs' \
-d @TweetsChampions.jsonThis will feed the TweetsChampions.json file to the core that we named championsTweets.
Real data isn’t perfect
But on my first attempt, as I returned with my coffee, I found this response from Solr:
{
"responseHeader":{
"status":400,
"QTime":996},
"error":{
"metadata":[
"error-class","org.apache.solr.common.SolrException",
"root-error-class","java.lang.NumberFormatException"],
"msg":"ERROR: [doc=1000365564320247808] Error adding field 'retweeted_status.user.profile_background_color'='9AE4E8' msg=For input string: \"9AE4E8\"",
"code":400}}So there was something wrong, and it was in a field named profile_background_color. Notice that Solr also informs us about the type of the error: it’s a number format exception. Oh? We recognize 9AE4E8 as an RGB value, but Solr seems to believe this is a number.
But isn’t this what the schemaless mode is supposed to handle? Shouldn’t it guess the fields types? Well, this actually means that Solr already has guessed that the value of this field is supposed to be a number. If we look inside the json file, we find the first occurence of the string 9AE4E8 on line 3. But the first occurence of the retweeted_status field is on line 2, and inside there, we quickly see that the value on path user.profile_background_color is set to "000000". It’s not a number in json, since it has the quotes, but Solr’s best guess was that it was a number anyway.
One way to fix this could be to change that value into something that cannot be interpreted as a number, e.g. "A00000". But that would be tampering with the data, and we don’t want to do that. Another way to do it is to find some element in the dataset where this value starts with a letter, and move that element to the top of the file. In that way, Solr will read that element first, and get the value right. On line 5, we seem to have found what we were looking for, so we move that line to the top of the file. We then save the file, delete the championsTweets core since Solr has gotten an opinion about the data in there already, recreate it and set autoCreateFields to true again, like the first time. And thereafter we relaunch the curl update command. (Warning: if you’re tempted to try this out step by step while reading, don’t act just yet!)
But then we get this same error for another field. This time it is retweeted_status.user.profile_text_color. And we realize that we cannot go on moving the data around in a 1.9Gb file if getting rid of one error merely brings up another. We would risk going on forever.
Using the Solr managed schema as a sparring partner
Instead, let’s turn to the files that Solr has created while trying to index our json file. We find what we’re looking for in /var/solr/data/championsTweets/conf/managed-schema. This is where the data types are defined.
Open the file and search for the word color. It appears several times. The first occurrence of it within a field tag is with the path retweeted_status.user.profile_background_color. This field tag defines that path as a text_general field. There are a few more field tags with color in them like this one, all configured as text_general, but then we get to retweeted_status.user.profile_text_color, which is defined as a plongs field. Let’s change that into text_general and then look for more colour fields to change. (And now, going step by step, you’re welcome to do it!) Only change in the field tags, and you’ll be fine. Save the file and reload the core for the changes to take effect:
curl "http://localhost:8983/solr/admin/cores?action=RELOAD&core=championsTweets"Then we need to remove the already imported tweet documents from the core, since they will have the wrong field type for those colour fields. The very simplest way to do so is to clear or flush all data from the core:
curl -X POST -H 'Content-Type: application/json' \
'http://localhost:8983/solr/championsTweets/update?commit=true' \
-d '{ "delete": {"query":"*:*"} }'… and finally launch our curl update command (like above) to import the data anew.
(If you encounter more errors like this one, simply go into the managed-schema file and do the needed corrections and then restart, like described above. Since our schema is being constructed during the data import, errors will appear as you go, and you are likely to have to repeat the correction maneuver several times. But when you see the amount of configuration inside the schema file, you will be glad you don’t have to define it all manually.)
Done in less than 10 minutes
If you succeeded in importing the json file in this manner, you should see output like this from the update command:
{
"responseHeader":{
"status":0,
"Qtime":455239}}As long as the status is 0, the import succeeded. You see the query time on my machine was 455 seconds, i.e. just above seven and a half minutes.
Now open the Solr http interface and select the championsTweets core. There should be more than 350 000 documents in there. (If not, restart the Solr service. Chances are they will turn up then.)

Do a search for «text:bale» and see if you too get 27515 hits for that search.
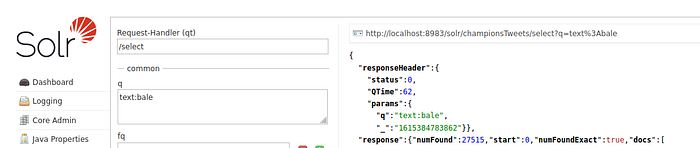
This shows that importing large documents with large json structures is actually easy and doesn’t demand a lot of definition work in Solr. Of course, this import isn’t really very good. For instance, one would like date definitions to be dates, not text strings. But you now have the managed-schema file to help you define the values − it’s a great starting point if you’re doing the job yourself afterwards. So even if you plan to do the field definitions «by hand», using the Solr schemaless mode import feature as a sparring partner is a very useful exercice on your way!
The official documents about schemaless importing of data are found here: https://solr.apache.org/guide/8_8/schemaless-mode.html
